# L'Analyse en Composantes Principales (ACP) en pratique avec Python
## Introduction
Bienvenue dans ce chapitre dédié à l'application pratique de l'Analyse en Composantes Principales (ACP) avec Python. Après avoir exploré les fondements théoriques de l'ACP dans le cadre de votre cours de "Data Mining avec Python", nous allons maintenant passer à la mise en œuvre concrète de cet outil puissant de réduction de dimensionnalité et de visualisation.
L'ACP est une technique non supervisée qui vise à transformer un ensemble de variables potentiellement corrélées en un ensemble de nouvelles variables non corrélées appelées **composantes principales**. Ces composantes sont ordonnées de manière à ce que les premières retiennent le maximum d'information (variance) des données originales. C'est un outil indispensable pour :
* Simplifier des jeux de données complexes.
* Réduire le bruit et la redondance.
* Faciliter la visualisation de données multidimensionnelles.
* Préparer les données pour d'autres algorithmes d'apprentissage automatique.
Dans ce chapitre, nous allons suivre un processus pas à pas :
1. **Chargement et préparation d'un jeu de données** issu de la bibliothèque `scikit-learn`.
2. **Réalisation de l'ACP** à l'aide de la classe `PCA` de `scikit-learn`.
3. **Interprétation des résultats**, incluant l'analyse de la variance expliquée, l'interprétation des composantes et la visualisation des données transformées.
# Préparation du jeu de données : Le dataset `Wine` de `scikit-learn`
Pour illustrer l'ACP, nous utiliserons le jeu de données `Wine` (vin) disponible dans `scikit-learn`. Ce dataset est un classique pour les problèmes de classification et de réduction de dimensionnalité. Il contient des mesures chimiques de différents vins.
## Chargement du dataset
Nous allons commencer par charger le dataset et l'explorer rapidement.
```python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_wine
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# Charger le dataset Wine
wine = load_wine()
X = wine.data # Les caractéristiques (features)
y = wine.target # Les étiquettes (classes de vin)
feature_names = wine.feature_names # Noms des caractéristiques
# Créer un DataFrame pour une meilleure visualisation
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
print("Aperçu des 5 premières lignes du dataset Wine :")
print(df.head())
print("\nForme du dataset (lignes, colonnes) :", df.shape)
print("\nNoms des caractéristiques :", feature_names)
print("\nNombre de classes de vin :", len(np.unique(y)))
```
> [!note]
> Le dataset `Wine` contient 178 échantillons (lignes) et 13 caractéristiques (colonnes) décrivant les propriétés chimiques des vins. Il y a 3 classes de vins différentes.
## Standardisation des données
> [!warning] Attention ! L'importance de la standardisation
> L'ACP est sensible à l'échelle des variables. Si une variable a une variance beaucoup plus grande qu'une autre, elle aura une influence disproportionnée sur les premières composantes principales. Il est donc **impératif de standardiser les données** (centrer et réduire) avant d'appliquer l'ACP. Cela garantit que chaque caractéristique contribue de manière égale à l'analyse.
La standardisation consiste à transformer les données de sorte qu'elles aient une moyenne nulle et un écart-type de 1. Nous utilisons `StandardScaler` de `scikit-learn` pour cela.
$
X_{scaled} = \frac{X - \mu}{\sigma}
$
Où $\mu$ est la moyenne et $\sigma$ est l'écart-type de la caractéristique.
```python
# Instancier le StandardScaler
scaler = StandardScaler()
# Appliquer la standardisation aux caractéristiques (X)
X_scaled = scaler.fit_transform(X)
print("\nForme des données standardisées :", X_scaled.shape)
print("Moyenne des 5 premières caractéristiques après standardisation (devrait être proche de 0) :")
print(X_scaled[:, :5].mean(axis=0))
print("Écart-type des 5 premières caractéristiques après standardisation (devrait être proche de 1) :")
print(X_scaled[:, :5].std(axis=0))
```
# Réalisation de l'ACP avec `scikit-learn`
Maintenant que nos données sont préparées, nous pouvons procéder à l'ACP. La classe `PCA` de `scikit-learn` est l'outil principal pour cela.
## Instanciation et ajustement du modèle PCA
Nous allons d'abord ajuster un modèle `PCA` sans spécifier le nombre de composantes principales (`n_components`). Cela nous permettra d'analyser la variance expliquée par chaque composante et de décider combien de composantes retenir.
```python
# Instancier le modèle PCA (sans spécifier n_components pour l'instant)
pca = PCA()
# Ajuster le modèle PCA sur les données standardisées
pca.fit(X_scaled)
print("Nombre de composantes principales extraites :", pca.n_components_)
```
> [!note]
> Par défaut, `PCA` extraira autant de composantes principales qu'il y a de caractéristiques dans les données d'entrée (ici, 13).
## Analyse de la variance expliquée
L'une des étapes les plus cruciales de l'ACP est l'analyse de la variance expliquée par chaque composante principale. Cela nous aide à déterminer le nombre optimal de composantes à conserver.
* `pca.explained_variance_ratio_` : Tableau contenant la proportion de variance expliquée par chaque composante principale.
* `pca.explained_variance_` : Tableau contenant la variance expliquée par chaque composante principale.
```python
# Variance expliquée par chaque composante
explained_variance_ratio = pca.explained_variance_ratio_
print("\nProportion de variance expliquée par chaque composante principale :")
print(explained_variance_ratio)
# Variance cumulée expliquée
cumulative_explained_variance = np.cumsum(explained_variance_ratio)
print("\nProportion cumulée de variance expliquée :")
print(cumulative_explained_variance)
```
## Le "Scree Plot" (Graphique des éboulis)
Le Scree Plot est un graphique qui montre la variance expliquée par chaque composante principale. Il est très utile pour identifier le "coude" (elbow point), qui suggère le nombre de composantes à retenir.
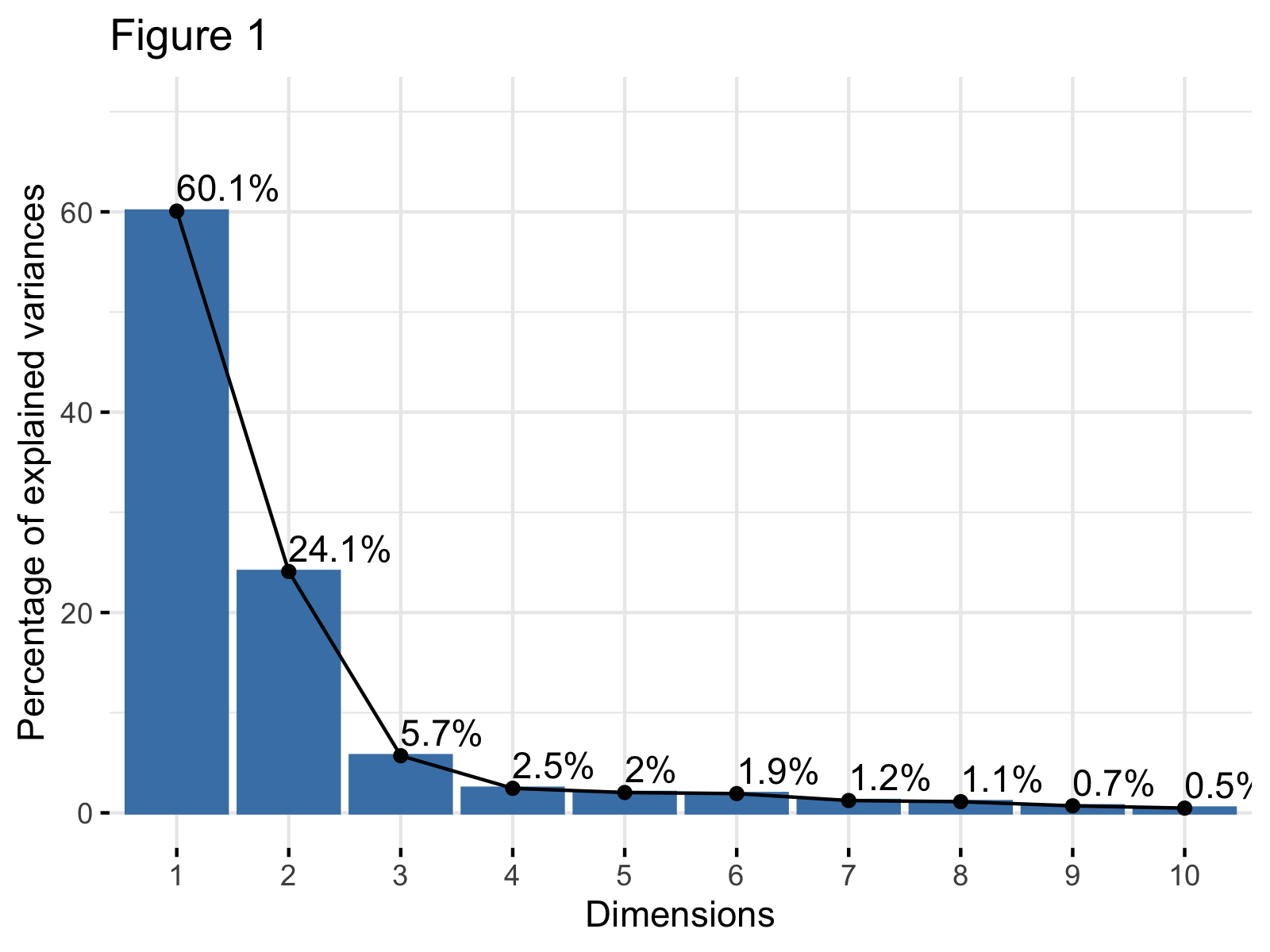
> [!tip] Comment interpréter un Scree Plot
> Recherchez un point où la pente de la courbe diminue brusquement. Les composantes avant ce point sont généralement considérées comme significatives, tandis que celles après contribuent beaucoup moins à la variance totale. Une règle empirique est de retenir suffisamment de composantes pour expliquer un certain pourcentage de la variance totale (par exemple, 80% ou 90%).
```python
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio, marker='o', linestyle='--', color='blue', label='Variance expliquée individuelle')
plt.plot(range(1, len(explained_variance_ratio) + 1), cumulative_explained_variance, marker='x', linestyle='-', color='red', label='Variance expliquée cumulée')
plt.title('Scree Plot : Variance expliquée par les composantes principales')
plt.xlabel('Numéro de la composante principale')
plt.ylabel('Proportion de variance expliquée')
plt.grid(True)
plt.legend()
plt.xticks(range(1, len(explained_variance_ratio) + 1))
plt.show()
```
À partir du Scree Plot, nous pouvons observer que les deux premières composantes principales expliquent une part significative de la variance. Par exemple, les deux premières composantes expliquent environ 56% de la variance cumulée, et les trois premières environ 67%. Pour la visualisation, il est courant de ne retenir que les deux ou trois premières composantes.
## Transformation des données
Une fois que nous avons choisi le nombre de composantes, nous pouvons transformer nos données originales en ce nouvel espace de dimensions réduites. Pour la visualisation, nous allons choisir 2 composantes principales.
```python
# Instancier PCA avec le nombre de composantes souhaité (par exemple, 2 pour la visualisation)
pca_final = PCA(n_components=2)
# Ajuster le modèle et transformer les données standardisées
X_pca = pca_final.fit_transform(X_scaled)
print("\nForme des données après transformation PCA (2 composantes) :", X_pca.shape)
print("Aperçu des 5 premières lignes des données transformées :")
print(pd.DataFrame(X_pca, columns=['PC1', 'PC2']).head())
```
> [!definition] Composantes Principales (CP)
> Les composantes principales sont de nouvelles variables créées comme des combinaisons linéaires des variables originales. Elles sont orthogonales entre elles (non corrélées) et captent le maximum de variance possible des données.
> Soit $X = [x_1, x_2, \dots, x_p]$ un vecteur de $p$ variables originales. Une composante principale $CP_k$ est définie par :
> $ CP_k = a_{k1}x_1 + a_{k2}x_2 + \dots + a_{kp}x_p $
> où les $a_{kj}$ sont les coefficients de chargement (loadings) qui représentent la contribution de chaque variable originale à cette composante.
# Interprétation des résultats de l'ACP
La transformation des données n'est que la première étape. L'interprétation des composantes principales est essentielle pour comprendre ce que ces nouvelles dimensions représentent.
## Interprétation des coefficients de chargement (Loadings)
Les coefficients de chargement (`pca.components_`) sont les vecteurs propres (eigenvectors) de la matrice de covariance (ou corrélation) des données. Chaque ligne de `pca.components_` représente une composante principale, et chaque colonne correspond à une caractéristique originale.
Les valeurs de ces coefficients indiquent la force et la direction de la relation entre la caractéristique originale et la composante principale.
```python
# Récupérer les coefficients de chargement (loadings)
loadings = pca_final.components_
# Créer un DataFrame pour une meilleure lisibilité
loadings_df = pd.DataFrame(loadings, index=['PC1', 'PC2'], columns=feature_names)
print("\nCoefficients de chargement (Loadings) :")
print(loadings_df)
```
> [!example] Interprétation de PC1 et PC2
> En regardant les chargements de `PC1` :
> * Des valeurs positives élevées pour `flavanoids`, `proline`, `total_phenols` indiquent que ces caractéristiques contribuent fortement et positivement à `PC1`.
> * Des valeurs négatives élevées pour `OD280/OD315_of_diluted_wines`, `color_intensity`, `malic_acid` indiquent que ces caractéristiques contribuent fortement et négativement à `PC1`.
> `PC1` semble donc capturer une dimension liée à la richesse en phénols et flavonoïdes, potentiellement associée à la qualité ou au type de vin, s'opposant à l'intensité de la couleur et l'acidité malique.
>
> Pour `PC2` :
> * `alcalinity_of_ash`, `magnesium`, `nonflavanoid_phenols` ont des chargements positifs élevés.
> * `alcohol`, `proanthocyanins` ont des chargements négatifs élevés.
> `PC2` semble représenter une dimension liée à l'alcalinité et au magnésium, s'opposant à l'alcool et aux proanthocyanines.
## Visualisation : Le Biplot
Le biplot est un graphique qui combine la visualisation des échantillons dans l'espace des composantes principales et la visualisation des vecteurs des caractéristiques originales. Il permet de comprendre simultanément comment les échantillons sont regroupés et quelles caractéristiques contribuent le plus à cette séparation.
```python
plt.figure(figsize=(12, 8))
# Scatter plot des échantillons dans l'espace des 2 premières CP
# Colorer les points par la classe de vin (y)
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=y, palette='viridis', s=100, alpha=0.8, legend='full')
# Ajouter les vecteurs des caractéristiques originales (loadings)
# Nous allons les mettre à l'échelle pour une meilleure visualisation
for i, feature in enumerate(feature_names):
plt.arrow(0, 0, loadings[0, i]*3, loadings[1, i]*3, color='red', alpha=0.7, head_width=0.05, head_length=0.05)
plt.text(loadings[0, i]*3.5, loadings[1, i]*3.5, feature, color='red', ha='center', va='center')
plt.title('Biplot de l\'ACP pour le dataset Wine')
plt.xlabel(f'Composante Principale 1 ({explained_variance_ratio[0]*100:.2f}% de variance expliquée)')
plt.ylabel(f'Composante Principale 2 ({explained_variance_ratio[1]*100:.2f}% de variance expliquée)')
plt.grid(True)
plt.axhline(0, color='gray', linestyle='--', linewidth=0.8)
plt.axvline(0, color='gray', linestyle='--', linewidth=0.8)
plt.show()
```
> [!tip] Comment interpréter un Biplot
> * **Proximité des points :** Les échantillons proches les uns des autres dans le biplot sont similaires en termes de leurs caractéristiques originales. On observe souvent des regroupements correspondant aux classes (comme ici pour les vins).
> * **Direction des vecteurs des caractéristiques :**
* Les caractéristiques dont les vecteurs pointent dans la même direction sont positivement corrélées.
* Les caractéristiques dont les vecteurs pointent dans des directions opposées sont négativement corrélées.
* Les caractéristiques dont les vecteurs sont orthogonaux (angle de 90°) sont non corrélées.
> * **Relation points-vecteurs :** Un échantillon est fortement caractérisé par les variables dont les vecteurs sont proches de lui dans le graphique. Par exemple, si un groupe de points est situé dans la direction d'un vecteur de caractéristique, cela signifie que ces échantillons ont des valeurs élevées pour cette caractéristique.
Dans notre biplot du dataset `Wine`, nous pouvons clairement voir :
* Une bonne séparation des trois classes de vin le long de la première composante principale (`PC1`).
* Les caractéristiques comme `flavanoids`, `proline`, `total_phenols` pointent vers la droite, indiquant qu'elles sont élevées pour les vins situés à droite sur `PC1`.
* Les caractéristiques comme `alcohol`, `malic_acid`, `color_intensity` pointent vers la gauche, indiquant qu'elles sont élevées pour les vins situés à gauche sur `PC1`.
* `PC2` sépare davantage les classes, avec des caractéristiques comme `alcalinity_of_ash` et `magnesium` pointant vers le haut, et `proanthocyanins` vers le bas.
# ➡️ C'est la fin !
Dans ce chapitre, nous avons parcouru les étapes pratiques de la réalisation d'une Analyse en Composantes Principales (ACP) avec Python, en utilisant les outils puissants de la bibliothèque `scikit-learn`. Nous avons vu comment :
1. **Préparer les données** en chargeant un dataset et en le standardisant, une étape cruciale pour la validité de l'ACP.
2. **Appliquer l'ACP** et analyser la variance expliquée par les composantes principales à l'aide du Scree Plot pour choisir le nombre optimal de dimensions.
3. **Interpréter les résultats** en examinant les coefficients de chargement des caractéristiques sur les composantes et en visualisant les données transformées via un Biplot.
L'ACP est une technique fondamentale en Data Science, non seulement pour la réduction de dimensionnalité et la visualisation, mais aussi comme étape préliminaire pour d'autres algorithmes d'apprentissage automatique. En réduisant le nombre de caractéristiques tout en conservant l'information essentielle, l'ACP peut améliorer les performances et la compréhensibilité des modèles de classification ou de régression.
Vous avez maintenant les compétences nécessaires pour appliquer l'ACP sur vos propres jeux de données et en interpréter les résultats de manière rigoureuse. C'est une base solide pour explorer des techniques plus avancées de réduction de dimensionnalité ou pour préparer vos données à des tâches d'apprentissage supervisé.
---
- Cours précèdent: [[Cours 1 - ACP]]
- Prochain cours: [[Cours 3 - ACP]]
- Page d'accueil de la compétence: [[ACP]]
# 🗓️ Historique
- Dernière MAJ: `20-Octobre-2025`
- Rédigé par: [[Hamilton DE ARAUJO]]