# Visuels pour Interpréter l'ACP
## Introduction
Bienvenue dans ce chapitre dédié à l'interprétation visuelle de l'Analyse en Composantes Principales (ACP). Après avoir exploré les fondements théoriques et l'implémentation de l'ACP en Python, il est crucial de savoir comment extraire du sens des résultats. L'ACP, par nature, transforme des données complexes en une représentation plus simple, mais cette simplification nécessite une interprétation attentive pour être utile.
Les visualisations sont des outils indispensables pour :
* Déterminer le nombre optimal de composantes principales à retenir.
* Comprendre les relations entre les variables d'origine et les nouvelles composantes.
* Identifier des groupes d'individus ou des *outliers*.
* Quantifier la contribution de chaque variable à la construction des composantes.
Dans ce cours, nous allons explorer les graphiques clés pour l'interprétation de l'ACP en utilisant les bibliothèques `matplotlib` et `seaborn`, des piliers de la visualisation de données en Python.
> [!note] Pré-requis
> Ce chapitre suppose une bonne compréhension des concepts fondamentaux de l'ACP (composantes principales, valeurs propres, variance expliquée) et une familiarité avec la manipulation de données en Python, notamment avec `pandas` et `scikit-learn` pour l'application de l'ACP.
# Les Visuels Essentiels pour l'Interprétation de l'ACP
Nous allons maintenant détailler les graphiques les plus couramment utilisés pour interpréter les résultats d'une ACP.
## L'Éboulis des Valeurs Propres (Scree Plot)
Le *scree plot* est le premier graphique à consulter après une ACP. Il permet de visualiser la part de variance expliquée par chaque composante principale et d'aider à déterminer le nombre optimal de composantes à retenir.
> [!definition] Scree Plot
> Un *scree plot* représente sur l'axe des abscisses le rang de la composante principale (CP1, CP2, ...) et sur l'axe des ordonnées la valeur propre associée (ou la variance expliquée).
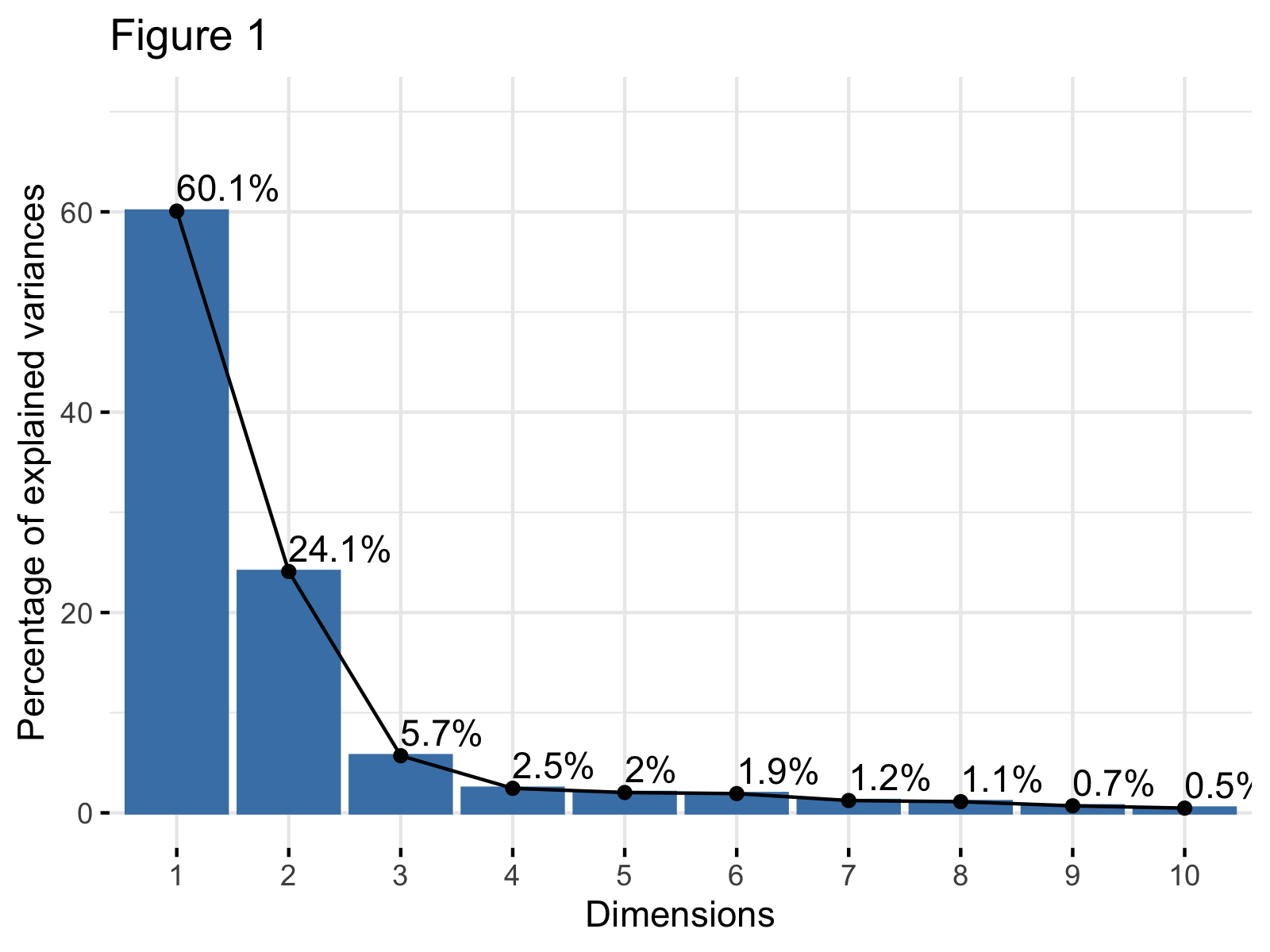
### Interprétation
* On cherche un "coude" ou un "point d'inflexion" dans la courbe. Les composantes avant ce coude sont généralement considérées comme significatives.
* La "règle de Kaiser" suggère de ne retenir que les composantes dont la valeur propre est supérieure à 1 (pour des données standardisées). Cependant, cette règle est souvent critiquée et le coude est une approche plus flexible.
* On peut aussi choisir de retenir un nombre de composantes qui expliquent un certain pourcentage cumulé de variance (ex: 80% ou 90%).
### Implémentation Python
```python
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# --- 1. Préparation des données (Exemple avec des données Iris) ---
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
# Standardisation des données
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Application de l'ACP
pca = PCA()
pca.fit(X_scaled)
# --- 2. Création du Scree Plot ---
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(pca.explained_variance_ratio_) + 1), pca.explained_variance_ratio_, marker='o', linestyle='--')
plt.title("Éboulis des Valeurs Propres (Scree Plot)")
plt.xlabel("Numéro de la Composante Principale")
plt.ylabel("Proportion de Variance Expliquée")
plt.grid(True)
plt.xticks(range(1, len(pca.explained_variance_ratio_) + 1))
plt.show()
# Variance expliquée cumulée
cumulative_variance = np.cumsum(pca.explained_variance_ratio_)
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(cumulative_variance) + 1), cumulative_variance, marker='o', linestyle='-')
plt.title("Variance Expliquée Cumulée")
plt.xlabel("Numéro de la Composante Principale")
plt.ylabel("Proportion Cumulée de Variance Expliquée")
plt.grid(True)
plt.xticks(range(1, len(cumulative_variance) + 1))
plt.axhline(y=0.90, color='r', linestyle='--', label='90% de variance')
plt.legend()
plt.show()
```
> [!example] Interprétation du Scree Plot
> Si le premier scree plot montre une forte chute après la deuxième ou troisième composante, cela suggère que deux ou trois CPs suffisent à capturer la majeure partie de l'information. Le second graphique vous aide à voir combien de CPs sont nécessaires pour atteindre, par exemple, 80% ou 90% de la variance totale.
## Le Cercle des Corrélations
Le cercle des corrélations est un graphique fondamental pour comprendre la relation entre les variables originales et les composantes principales. Il est généralement tracé pour les deux premières composantes principales (CP1 et CP2), qui sont souvent les plus interprétables.
> [!definition] Cercle des Corrélations
> Le cercle des corrélations représente les variables originales comme des vecteurs dans le plan factoriel formé par deux composantes principales (généralement CP1 et CP2). La longueur et la direction de chaque vecteur indiquent la corrélation de la variable avec les composantes.
### Interprétation
* **Longueur du vecteur**: Plus un vecteur est long (proche du cercle unitaire), plus la variable est bien représentée sur le plan factoriel et plus sa contribution à la construction des composantes est importante.
* **Angle entre un vecteur et un axe**: Le cosinus de l'angle entre le vecteur d'une variable et l'axe d'une composante principale est égal à la corrélation entre cette variable et cette composante.
* Un angle proche de 0° ou 180° indique une forte corrélation (positive ou négative).
* Un angle proche de 90° ou 270° indique une faible corrélation.
* **Angle entre deux vecteurs de variables**: L'angle entre deux vecteurs de variables indique leur corrélation mutuelle.
* Variables proches (petit angle) sont positivement corrélées.
* Variables opposées (angle proche de 180°) sont négativement corrélées.
* Variables orthogonales (angle proche de 90°) sont non corrélées.
### Implémentation Python
Pour construire le cercle des corrélations, nous avons besoin des coordonnées des variables sur les composantes principales. Ces coordonnées sont les corrélations entre les variables originales et les composantes principales.
```python
# --- 1. Calcul des coordonnées des variables sur les CPs ---
# Les "loadings" sont les coefficients des vecteurs propres.
# Pour obtenir les corrélations, on multiplie les loadings par la racine carrée des valeurs propres.
# Ou plus simplement, on peut calculer la corrélation entre les variables originales et les scores des CPs.
# Scores des individus sur les CPs
X_projected = pca.transform(X_scaled)
# Calcul des corrélations entre les variables originales et les deux premières CPs
correlations = np.corrcoef(X_scaled.T, X_projected[:, :2].T)
# On ne prend que la partie des corrélations entre les variables originales et les CPs
# La matrice de corrélation complète serait (n_features + n_components) x (n_features + n_components)
# Nous voulons les n_features premières lignes (variables originales) et les 2 dernières colonnes (CP1, CP2)
correlations_vars_cps = correlations[:X_scaled.shape[1], X_scaled.shape[1]:]
# --- 2. Création du Cercle des Corrélations ---
plt.figure(figsize=(8, 8))
# Dessiner le cercle unitaire
circle = plt.Circle((0, 0), 1, color='gray', fill=False, linestyle='--')
plt.gca().add_patch(circle)
# Dessiner les vecteurs pour chaque variable
for i, (x, y) in enumerate(correlations_vars_cps):
plt.arrow(0, 0, x, y, color='b', alpha=0.8, head_width=0.05, head_length=0.05)
plt.text(x * 1.15, y * 1.15, feature_names[i], color='b', ha='center', va='center')
plt.xlim(-1.2, 1.2)
plt.ylim(-1.2, 1.2)
plt.xlabel(f"Composante Principale 1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"Composante Principale 2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.title("Cercle des Corrélations")
plt.grid(True)
plt.axhline(0, color='gray', linestyle='--', linewidth=0.8)
plt.axvline(0, color='gray', linestyle='--', linewidth=0.8)
plt.show()
```
> [!tip] Astuce pour le cercle des corrélations
> Pour des analyses plus poussées, des bibliothèques comme `factor_analyzer` ou `prince` peuvent offrir des fonctions intégrées pour générer ce type de graphique, mais il est essentiel de comprendre comment le construire manuellement avec `matplotlib`.
## Projection des Individus (Scatter Plot des Individus)
Ce graphique permet de visualiser la position de chaque individu (observation) dans le plan factoriel défini par deux composantes principales.
> [!definition] Projection des Individus
> C'est un nuage de points où chaque point représente un individu, projeté sur un plan formé par deux composantes principales (souvent CP1 et CP2).
### Interprétation
* **Proximité des points**: Les individus qui sont proches sur le graphique sont similaires en termes de variables originales.
* **Groupes**: Si des groupes d'individus apparaissent, cela suggère une structure sous-jacente dans les données. L'utilisation de couleurs ou de marqueurs différents pour des catégories connues (si disponibles) peut révéler ces groupes.
* **Outliers**: Les points éloignés de la masse des autres points peuvent être des *outliers*.
### Implémentation Python
```python
import seaborn as sns
# --- 1. Récupération des scores des individus sur les CPs ---
# X_projected contient les scores de tous les individus sur toutes les CPs
# Nous nous concentrons sur les deux premières CPs pour la visualisation
df_projected = pd.DataFrame(data=X_projected[:, :2], columns=['CP1', 'CP2'])
df_projected['Target'] = iris.target # Ajout des labels pour la coloration
df_projected['Target_Names'] = iris.target_names[iris.target]
# --- 2. Création du Scatter Plot des Individus ---
plt.figure(figsize=(10, 8))
sns.scatterplot(x='CP1', y='CP2', hue='Target_Names', data=df_projected,
s=100, alpha=0.8, palette='viridis') # s pour la taille des points
plt.xlabel(f"Composante Principale 1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"Composante Principale 2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.title("Projection des Individus sur le Plan Factoriel (CP1 vs CP2)")
plt.grid(True)
plt.axhline(0, color='gray', linestyle='--', linewidth=0.8)
plt.axvline(0, color='gray', linestyle='--', linewidth=0.8)
plt.legend(title='Espèce')
plt.show()
```
> [!tip] Utilisation de `seaborn`
> `seaborn` est particulièrement utile ici pour ajouter de la couleur ou des formes basées sur des variables catégorielles (comme `Target_Names` dans l'exemple Iris), ce qui facilite grandement l'identification de groupes.
## Biplot (Graphique des Individus et des Variables)
Le biplot combine les informations du cercle des corrélations et de la projection des individus sur un même graphique. C'est un outil très puissant pour une interprétation conjointe.
> [!definition] Biplot
> Un biplot affiche simultanément les points représentant les individus et les vecteurs représentant les variables originales sur le même plan factoriel.
### Interprétation
* **Relations Individus-Variables**: Un individu situé dans la direction d'un vecteur de variable a une valeur élevée pour cette variable. Inversement, un individu dans la direction opposée a une faible valeur.
* **Groupes d'Individus et Caractéristiques**: Si un groupe d'individus se forme dans une certaine région du plan, les vecteurs de variables pointant dans cette même direction caractérisent ce groupe.
* **Attention**: L'échelle des individus et des variables n'est pas la même. On interprète les directions et les proximités, mais pas directement les distances entre un individu et un vecteur.
### Implémentation Python
La création d'un biplot nécessite de superposer les deux graphiques précédents.
```python
plt.figure(figsize=(12, 10))
# --- 1. Projection des Individus ---
sns.scatterplot(x='CP1', y='CP2', hue='Target_Names', data=df_projected,
s=100, alpha=0.6, palette='viridis', legend=False) # Pas de légende ici pour éviter la surcharge
# --- 2. Cercle des Corrélations (superposé) ---
# Normalisation des vecteurs pour qu'ils soient bien visibles sur le même graphique que les individus
# La longueur des flèches doit être mise à l'échelle pour être lisible avec les points des individus.
# Une approche courante est de multiplier les loadings par un facteur d'échelle.
# Les loadings sont pca.components_
loadings = pca.components_[:2].T # Transposé pour avoir les variables en lignes et les CPs en colonnes
# Facteur d'échelle pour les flèches
# Une heuristique est de mettre à l'échelle les loadings par la racine carrée de la variance expliquée
# ou simplement par un facteur visuel pour qu'ils ne soient pas trop petits ou trop grands.
scale_factor = 2.5 # Ajuster ce facteur selon la dispersion des points
for i, (x, y) in enumerate(loadings):
plt.arrow(0, 0, x * scale_factor, y * scale_factor, color='r', alpha=0.8, head_width=0.05, head_length=0.05)
plt.text(x * scale_factor * 1.15, y * scale_factor * 1.15, feature_names[i], color='r', ha='center', va='center')
plt.xlim(X_projected[:,0].min()*1.2, X_projected[:,0].max()*1.2) # Ajuste les limites pour les individus
plt.ylim(X_projected[:,1].min()*1.2, X_projected[:,1].max()*1.2)
plt.xlabel(f"Composante Principale 1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"Composante Principale 2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.title("Biplot (Individus et Variables)")
plt.grid(True)
plt.axhline(0, color='gray', linestyle='--', linewidth=0.8)
plt.axvline(0, color='gray', linestyle='--', linewidth=0.8)
# Ajout d'une légende pour les individus (manuellement ou en réactivant la légende seaborn)
# Pour une légende plus propre, on peut la créer séparément ou utiliser un hack avec plt.plot
unique_targets = df_projected['Target_Names'].unique()
colors = sns.color_palette('viridis', n_colors=len(unique_targets))
handles = [plt.Line2D([0], [0], marker='o', color='w', label=label,
markerfacecolor=colors[i], markersize=10)
for i, label in enumerate(unique_targets)]
plt.legend(handles=handles, title='Espèce des Individus', loc='upper left')
plt.show()
```
> [!warning] Interprétation du Biplot
> Soyez prudent avec l'interprétation des distances entre les variables et les individus. Le biplot est principalement destiné à montrer les *directions* des relations. La longueur des flèches des variables est souvent mise à l'échelle pour la lisibilité et ne représente pas directement la variance expliquée par la variable.
## Contribution des Variables aux Composantes
Il est utile de quantifier et de visualiser la contribution de chaque variable originale à la formation de chaque composante principale.
> [!definition] Contribution des Variables
> La contribution d'une variable à une composante principale est une mesure de l'importance de cette variable dans la construction de cette composante. Elle est souvent calculée comme le carré du cosinus de l'angle entre la variable et la composante, ou comme le carré des coefficients du vecteur propre (loadings) normalisé.
### Calcul de la contribution
La contribution d'une variable $j$ à la composante $k$ peut être calculée comme :
$
\text{Contrib}(v_j, CP_k) = \frac{\text{loading}(v_j, CP_k)^2 \times \lambda_k}{\sum_{l=1}^{p} \text{loading}(v_l, CP_k)^2 \times \lambda_k} \times 100
$
où $\text{loading}(v_j, CP_k)$ est le coefficient de la variable $j$ sur la composante $k$, et $\lambda_k$ est la valeur propre de la composante $k$.
Une manière plus simple est de considérer les valeurs absolues des loadings.
### Implémentation Python
```python
# --- 1. Calcul des contributions (utilisant les loadings) ---
# Loadings (coefficients des vecteurs propres)
loadings_df = pd.DataFrame(pca.components_, columns=feature_names,
index=[f'CP{i+1}' for i in range(pca.n_components_)])
# Pour simplifier, nous allons visualiser l'importance relative des loadings pour chaque CP
# On peut aussi prendre les valeurs absolues des loadings pour voir l'ampleur de la contribution
# sans la direction.
# Ou calculer la contribution au sens statistique (cos2) si nécessaire.
# Pour une interprétation simple, les loadings eux-mêmes sont très informatifs.
# Visualisation des loadings pour les deux premières CPs
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
sns.barplot(x=loadings_df.loc['CP1'].index, y=loadings_df.loc['CP1'].values, palette='viridis')
plt.title("Loadings des Variables sur CP1")
plt.ylabel("Valeur du Loading")
plt.xticks(rotation=45, ha='right')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.subplot(1, 2, 2)
sns.barplot(x=loadings_df.loc['CP2'].index, y=loadings_df.loc['CP2'].values, palette='viridis')
plt.title("Loadings des Variables sur CP2")
plt.ylabel("Valeur du Loading")
plt.xticks(rotation=45, ha='right')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
```
> [!note] Interprétation des Loadings
> * Un *loading* élevé (en valeur absolue) indique que la variable contribue fortement à cette composante.
> * Le signe du *loading* indique la direction de la corrélation : un *loading* positif signifie que la variable augmente avec la composante, un *loading* négatif signifie qu'elle diminue.
> * Ces graphiques sont complémentaires au cercle des corrélations, offrant une vue plus quantitative.
# Mise en Œuvre Pratique avec Python (Récapitulatif et Code Complet)
Récapitulons l'ensemble du processus avec un exemple complet, incluant l'importation des données, le pré-traitement, l'ACP et la génération des visuels.
```python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# --- 1. Chargement et Préparation des Données ---
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
# Création d'un DataFrame pour une meilleure manipulation
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
df['species'] = target_names[y]
print("Aperçu des données :")
print(df.head())
print("\nStatistiques descriptives :")
print(df.describe())
# Standardisation des données
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
df_scaled = pd.DataFrame(X_scaled, columns=feature_names)
# --- 2. Application de l'ACP ---
pca = PCA()
pca.fit(X_scaled)
# Projection des données sur les composantes principales
X_projected = pca.transform(X_scaled)
df_projected = pd.DataFrame(data=X_projected,
columns=[f'CP{i+1}' for i in range(pca.n_components_)])
df_projected['target'] = y
df_projected['species'] = target_names[y]
# --- 3. Génération des Visuels ---
# 3.1. Éboulis des Valeurs Propres (Scree Plot)
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(pca.explained_variance_ratio_) + 1), pca.explained_variance_ratio_, marker='o', linestyle='--')
plt.title("Éboulis des Valeurs Propres (Scree Plot)")
plt.xlabel("Numéro de la Composante Principale")
plt.ylabel("Proportion de Variance Expliquée")
plt.grid(True)
plt.xticks(range(1, len(pca.explained_variance_ratio_) + 1))
plt.show()
cumulative_variance = np.cumsum(pca.explained_variance_ratio_)
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(cumulative_variance) + 1), cumulative_variance, marker='o', linestyle='-')
plt.title("Variance Expliquée Cumulée")
plt.xlabel("Numéro de la Composante Principale")
plt.ylabel("Proportion Cumulée de Variance Expliquée")
plt.grid(True)
plt.xticks(range(1, len(cumulative_variance) + 1))
plt.axhline(y=0.90, color='r', linestyle='--', label='90% de variance')
plt.legend()
plt.show()
# 3.2. Cercle des Corrélations (pour CP1 et CP2)
# Calcul des corrélations entre les variables originales et les deux premières CPs
# Les loadings sont les coefficients des vecteurs propres.
# pca.components_ a la forme (n_components, n_features)
# Pour le cercle, on utilise les loadings des deux premières CPs
loadings_cp1_cp2 = pca.components_[:2].T # Transposé pour avoir (n_features, 2)
plt.figure(figsize=(8, 8))
circle = plt.Circle((0, 0), 1, color='gray', fill=False, linestyle='--')
plt.gca().add_patch(circle)
for i, (x, y) in enumerate(loadings_cp1_cp2):
plt.arrow(0, 0, x, y, color='b', alpha=0.8, head_width=0.05, head_length=0.05)
plt.text(x * 1.15, y * 1.15, feature_names[i], color='b', ha='center', va='center')
plt.xlim(-1.2, 1.2)
plt.ylim(-1.2, 1.2)
plt.xlabel(f"Composante Principale 1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"Composante Principale 2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.title("Cercle des Corrélations")
plt.grid(True)
plt.axhline(0, color='gray', linestyle='--', linewidth=0.8)
plt.axvline(0, color='gray', linestyle='--', linewidth=0.8)
plt.show()
# 3.3. Projection des Individus (pour CP1 et CP2)
plt.figure(figsize=(10, 8))
sns.scatterplot(x='CP1', y='CP2', hue='species', data=df_projected,
s=100, alpha=0.8, palette='viridis')
plt.xlabel(f"Composante Principale 1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"Composante Principale 2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.title("Projection des Individus sur le Plan Factoriel (CP1 vs CP2)")
plt.grid(True)
plt.axhline(0, color='gray', linestyle='--', linewidth=0.8)
plt.axvline(0, color='gray', linestyle='--', linewidth=0.8)
plt.legend(title='Espèce')
plt.show()
# 3.4. Biplot (Individus et Variables pour CP1 et CP2)
plt.figure(figsize=(12, 10))
# Individus
sns.scatterplot(x='CP1', y='CP2', hue='species', data=df_projected,
s=100, alpha=0.6, palette='viridis', legend=False)
# Variables
scale_factor = 2.5 # Ajuster ce facteur selon la dispersion des points
for i, (x, y) in enumerate(loadings_cp1_cp2):
plt.arrow(0, 0, x * scale_factor, y * scale_factor, color='r', alpha=0.8, head_width=0.05, head_length=0.05)
plt.text(x * scale_factor * 1.15, y * scale_factor * 1.15, feature_names[i], color='r', ha='center', va='center')
plt.xlim(df_projected['CP1'].min()*1.2, df_projected['CP1'].max()*1.2)
plt.ylim(df_projected['CP2'].min()*1.2, df_projected['CP2'].max()*1.2)
plt.xlabel(f"Composante Principale 1 ({pca.explained_variance_ratio_[0]*100:.1f}%)")
plt.ylabel(f"Composante Principale 2 ({pca.explained_variance_ratio_[1]*100:.1f}%)")
plt.title("Biplot (Individus et Variables)")
plt.grid(True)
plt.axhline(0, color='gray', linestyle='--', linewidth=0.8)
plt.axvline(0, color='gray', linestyle='--', linewidth=0.8)
unique_targets = df_projected['species'].unique()
colors = sns.color_palette('viridis', n_colors=len(unique_targets))
handles = [plt.Line2D([0], [0], marker='o', color='w', label=label,
markerfacecolor=colors[i], markersize=10)
for i, label in enumerate(unique_targets)]
plt.legend(handles=handles, title='Espèce des Individus', loc='upper left')
plt.show()
# 3.5. Contribution des Variables aux Composantes (Loadings)
loadings_df = pd.DataFrame(pca.components_, columns=feature_names,
index=[f'CP{i+1}' for i in range(pca.n_components_)])
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
sns.barplot(x=loadings_df.loc['CP1'].index, y=loadings_df.loc['CP1'].values, palette='viridis')
plt.title("Loadings des Variables sur CP1")
plt.ylabel("Valeur du Loading")
plt.xticks(rotation=45, ha='right')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.subplot(1, 2, 2)
sns.barplot(x=loadings_df.loc['CP2'].index, y=loadings_df.loc['CP2'].values, palette='viridis')
plt.title("Loadings des Variables sur CP2")
plt.ylabel("Valeur du Loading")
plt.xticks(rotation=45, ha='right')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
```
# ➡️ C'est la fin !
L'Analyse en Composantes Principales est un outil puissant de réduction de dimensionnalité, mais sa véritable valeur réside dans la capacité à interpréter ses résultats. Les visualisations que nous avons explorées – l'éboulis des valeurs propres, le cercle des corrélations, la projection des individus et le biplot – sont indispensables à cette tâche.
Maîtriser ces graphiques avec `matplotlib` et `seaborn` vous permettra de :
* Prendre des décisions éclairées sur le nombre de composantes à retenir.
* Comprendre la structure sous-jacente de vos données.
* Identifier les variables les plus influentes.
* Détecter des groupes d'individus ou des *outliers*.
Ces compétences sont fondamentales pour toute analyse de données exploratoire et constituent une base solide pour des techniques d'apprentissage automatique plus avancées, où les composantes principales peuvent servir de nouvelles caractéristiques pour la modélisation (par exemple, en clustering ou en classification).
---
- Cours précèdent: [[Cours 2 - ACP]]
- Prochain cours: [[Exercices - ACP]]
- Page d'accueil de la compétence: [[ACP]]
# 🗓️ Historique
- Dernière MAJ: `20-Octobre-2025`
- Rédigé par: [[Hamilton DE ARAUJO]]